Módulo 2: Librerías básicas para el análisis de datos en Python
Nos complace presentarte el Módulo 2
En este módulo, nos adentraremos en el poderoso mundo del análisis y la visualización de datos utilizando algunas de las librerías esenciales de Python. Aprenderás a manejar estructuras de datos avanzadas con pandas, a realizar manipulaciones básicas y complejas en DataFrames, y a importar y exportar datos en varios formatos.
Además, exploraremos cómo crear y personalizar gráficos con matplotlib para representar visualmente tus datos de manera efectiva. Este módulo está diseñado para proporcionarte una base sólida que será fundamental para tus futuras aplicaciones en el análisis de datos. ¡Estamos emocionados de acompañarte en este viaje de aprendizaje!
Objetivo de aprendizaje:
Aprender los conceptos básicos y aplicaciones con librerías de Python diseñadas para el análisis y visualización de la información de manera que se desarrollen bases sólidas para las aplicaciones posteriores.
Contenidos:
- Estructuras de datos en Pandas: Series y DataFrames.
- Manipulación básica de DataFrames en Pandas: selección, filtrado, agregación.
- Importar y exportar datos guardados en distintos formatos.
- Creación de gráficos básicos en Matplotlib.
- Personalización y parametrización de las visualizaciones.
- Exportación de gráficos.
Material para el desarrollo de la sesión:
A continuación, encontrarás los enlaces a los notebooks de Google Colab que utilizaremos en la Sesión 2. Uno está dedicado a pandas, donde exploraremos estructuras de datos y manipulaciones básicas, y el otro se centra en matplotlib, para la creación y personalización de gráficos. Estos recursos te permitirán seguir de cerca los ejemplos y prácticas durante la sesión.
Links Colab Notebooks: sesión 2
pandas: herramienta esencial para el análisis de datos en Python
pandas es una biblioteca fundamental en Python, diseñada específicamente para la manipulación y el análisis de datos. Es utilizada ampliamente en la ciencia de datos, la ingeniería de datos y el análisis estadístico, gracias a su capacidad para manejar grandes volúmenes de datos de manera eficiente y su sintaxis intuitiva.
Documentación de la librería
Para aprovechar al máximo las capacidades de pandas en el análisis y manipulación de datos, te recomendamos consultar la documentación oficial de pandas.
La documentación es un recurso invaluable que proporciona una guía completa sobre todas las funciones y características de pandas. Desde tutoriales básicos hasta ejemplos avanzados, la documentación te ayudará a comprender cómo utilizar pandas de manera efectiva para tus proyectos. Es una herramienta esencial para resolver dudas, aprender nuevas técnicas y profundizar en las capacidades de esta poderosa biblioteca.
Características principales:
- Ofrece estructuras de datos flexibles y eficientes para el manejo de datos tabulares y series temporales.
- Proporciona herramientas para la limpieza, transformación y análisis de datos.
- Permite la importación y exportación de datos en diversos formatos, como CSV, Excel, SQL y HDF5.
- Integra funcionalidades avanzadas para el filtrado, la agregación y la visualización de datos.
- Es compatible con la integración de datos de múltiples fuentes y la creación de análisis complejos.
Empezar a usar pandas
Para empezar a usar pandas, primero debes importar el paquete. La comunidad generalmente utiliza el alias pd para pandas, por lo que es una práctica común en toda la documentación de pandas cargar el paquete con este alias.
import pandas as pd
I. Estructuras de datos flexibles
- Series: Una serie es un objeto unidimensional que contiene una secuencia de valores y una secuencia de etiquetas asociadas a cada valor. Puedes pensar en una serie como una columna de una tabla de datos.
- Creación de una serie:
pd.Series(data, index) - Acceso a elementos:
serie[index] - Operaciones matemáticas:
serie + serie - DataFrames: Un DataFrame es una estructura de datos bidimensional que contiene una colección ordenada de columnas, cada una de las cuales puede ser de un tipo diferente. Puedes pensar en un DataFrame como una tabla de datos.
- Creación de un DataFrame:
pd.DataFrame(data, columns) - Acceso a columnas:
df['columna'] - Operaciones de filtrado:
df[df['columna'] > valor]
Ejemplo:
A continuación, se presentan ejemplos prácticos de cómo crear objetos Series en pandas y combinarlos en un DataFrame.
La imagen que se presenta a continuación, ilustra cómo combinar tres Series de Pandas en un solo DataFrame. En la primera serie ("Series 1"), cada persona está asociada con su edad; en la segunda serie ("Series 2"), con su ciudad; y en la tercera serie ("Series 3"), con su puntaje. Al combinar estas tres series por su índice común, se crea un DataFrame completo que incluye la edad, ciudad y puntaje de cada persona. Esta visualización demuestra cómo las series individuales se pueden consolidar en un DataFrame para facilitar el análisis de datos en Pandas.

Puedes copiar las siguientes líneas de código y probarlo en un Colab Notebook (o en un Jupyter Notebook, si estás trabajando en un entorno local) para ver los resultados. Al ejecutar el código, obtendrás las Series individuales y el DataFrame final, que se verá como en la figura mostrada anteriormente, con las Series de edades, ciudades y puntajes combinadas en una estructura tabular.
1. Series de números enteros:
# Crear un objeto "Series" de números enteros
serie_edades = pd.Series([23, 35, 22, 28], index = ['Ana', 'Juan', 'Pedro', 'María'])
print(serie_edades)
2. Series de cadenas de texto:
# Crear un objeto "Series" de cadenas de texto
serie_ciudades = pd.Series(['Bogotá', 'Cali', 'Medellín', 'Tunja'], index = ['Ana', 'Juan', 'Pedro', 'María'])
print(serie_ciudades)
3. Series de números decimales:
# Crear un objeto "Series" de números flotantes
serie_puntajes = pd.Series([85.5, 92.3, 76.8, 88.1], index = ['Ana', 'Juan', 'Pedro', 'María'])
print(serie_puntajes)
Combinación de Series en un DataFrame
A continuación, combinamos las Series anteriores para crear un DataFrame:
# Crear un DataFrame a partir de "Series"
data = {'Edad': serie_edades, 'Ciudad': serie_ciudades, 'Puntaje': serie_puntajes}
df = pd.DataFrame(data)
print(df)
II. Manipulación y Transformación de Datos
- Filtrado y Selección: Métodos intuitivos para seleccionar y filtrar datos usando condiciones, etiquetas y posiciones.
- Filtrado por condición:
df[df['columna'] > valor] - Selección por etiqueta:
df.loc['etiqueta'] - Selección por posición:
df.iloc[posición] - Agrupamiento: Operaciones de agrupación (groupby) que facilitan el resumen y la agregación de datos.
- Agrupar por columna:
df.groupby('columna') - Aplicar funciones de agregación:
df.groupby('columna').agg(función) - Transformaciones: Funciones de aplicación (apply), mapear (map), y funciones vectorizadas que permiten transformaciones eficientes.
- Aplicar función a columnas:
df['columna'].apply(función) - Aplicar función a elementos:
df.applymap(función)
Ejemplo:
A partir del DataFrame anterior df, realizaremos varias operaciones de manipulación y transformación de datos. Estas operaciones incluyen filtrado y selección, agrupamiento, y transformaciones, que aplican funciones a los datos para realizar cambios eficientes. Estas técnicas son esenciales para el análisis y manejo efectivo de datos en Pandas.
1. Filtrado y Selección:
- Filtrar las personas con un puntaje mayor a 80.
# Personas con puntaje mayor a 80
filtro_puntaje = df[df['Puntaje'] > 80]
print(filtro_puntaje)
- Seleccionar la información de Juan.
iloc: es útil cuando se trabaja con posiciones y índices numéricos.
# Seleccionar la información de Juan usando iloc
juan_info_iloc = df.iloc[1]
print(juan_info_iloc )
loc: es más intuitivo cuando se trabaja con etiquetas y nombres.
# Seleccionar la información de Juan usando loc
juan_info_loc = df.loc['Juan']
print(juan_info_loc)
2. Agrupamiento:
- Agrupar los datos por la columna "Ciudad" y calcula el puntaje promedio para cada ciudad.
# Puntaje promedio por ciudad
agrupamiento_ciudad = df.groupby('Ciudad')['Puntaje'].mean()
print(agrupamiento_ciudad)
3. Transformaciones:
- Crear una nueva columna "Puntaje_Ajustado" que incrementa cada puntaje en 5 puntos.
# Nueva columna 'Puntaje_Ajustado' con incremento de 5 puntos
df['Puntaje_Ajustado'] = df['Puntaje'].apply(lambda x: x + 5)
print(df)
III. Manejo de Datos Faltantes
- Identificación: Métodos para detectar y manejar valores nulos o faltantes en los datos.
- Identificar valores nulos:
df.isnull() - Eliminar filas con valores nulos:
df.dropna() - Reemplazar valores nulos:
df.fillna(valor)
IV. Entrada y Salida de Datos (I/O)
- Importación: Métodos para cargar datos desde archivos locales o remotos en diferentes formatos.
- Desde CSV:
pd.read_csv('archivo.csv') - Desde Excel:
pd.read_excel('archivo.xlsx') - Desde Stata:
pd.read_stata('archivo.dta') - Desde SQL:
pd.read_sql('SELECT * FROM tabla', conexión) - Exportación: Métodos para guardar datos en archivos locales o remotos en diferentes formatos.
- Exportar a CSV:
df.to_csv('archivo.csv') - Exportar a Excel:
df.to_excel('archivo.xlsx') - Exportar a Stata:
df.to_stata('archivo.dta') - Exportar a SQL:
df.to_sql('tabla', conexión)
V. Visualización de Datos
- Gráficos: Funciones para crear visualizaciones de datos atractivas y efectivas.
- Gráfico de barras:
df.plot.bar() - Gráfico de líneas:
df.plot.line() - Gráfico de dispersión:
df.plot.scatter() - Gráfico de cajas:
df.plot.box()
Estas son solo algunas de las muchas funcionalidades que ofrece Pandas para el análisis y manipulación de datos. La documentación oficial de Pandas es un recurso invaluable que te permitirá explorar todas las funciones y características de la librería, así como aprender nuevas técnicas y aplicaciones para tus proyectos de análisis de datos.
Para profundizar en el uso de Pandas y adquirir una comprensión más profunda de sus capacidades, te recomendamos explorar la documentación oficial de Pandas y realizar ejercicios prácticos en un entorno de desarrollo como Google Colab o Jupyter Notebook. La práctica constante y la experimentación te ayudarán a consolidar tus conocimientos y a adquirir habilidades avanzadas en el manejo de datos con Pandas.
Matplotlib: Librería de Visualización de Datos en Python
Matplotlib es una biblioteca fundamental en Python para la creación de gráficos y visualización de datos. Utilizada ampliamente en ciencia de datos, investigación y análisis de datos, Matplotlib permite la generación de una amplia variedad de gráficos, desde simples gráficos de líneas hasta complejas visualizaciones en 2D y 3D.
Documentación de la librería
Para aprovechar al máximo las capacidades de Matplotlib en la visualización de datos, te recomendamos visitar la documentación oficial de Matplotlib. Este recurso proporciona guías detalladas, tutoriales y ejemplos que te ayudarán a dominar la creación de gráficos y personalizaciones avanzadas, mejorando así tus habilidades en el análisis visual de datos.
Características principales:
- Ofrece una amplia variedad de gráficos y visualizaciones, incluyendo gráficos de líneas, barras, dispersión, cajas, histogramas y más.
- Proporciona herramientas para personalizar la apariencia de los gráficos, incluyendo colores, estilos, etiquetas y títulos.
- Permite la creación de gráficos en 2D y 3D, así como la superposición de múltiples gráficos en una sola figura.
- Es compatible con la exportación de gráficos en diversos formatos, como PNG, JPG, PDF y SVG.
- Integra funcionalidades avanzadas para la visualización de datos en tiempo real, la animación y la interactividad.
Empezar a usar Matplotlib
Para empezar a usar Matplotlib, primero debes importar el paquete. La comunidad generalmente utiliza el alias plt para Matplotlib, por lo que es una práctica común en toda la documentación de Matplotlib cargar el paquete con este alias.
import matplotlib.pyplot as plt
Una vez que hayas importado Matplotlib, puedes empezar a crear gráficos y visualizaciones de datos. A continuación, se presentan ejemplos prácticos de cómo crear diferentes tipos de gráficos en Matplotlib, desde gráficos de líneas y barras hasta gráficos de dispersión y cajas.
Ejemplo:
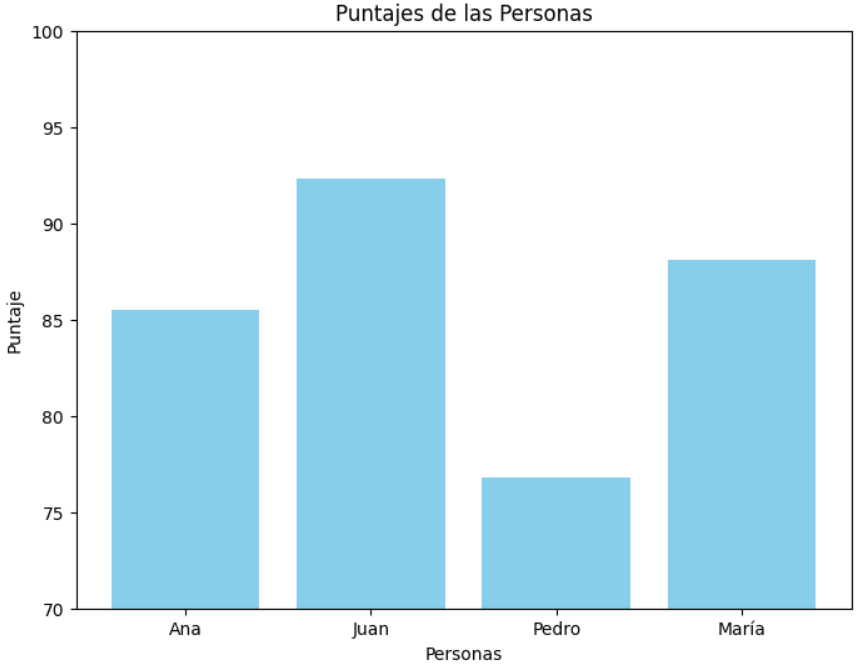
Utilizando los datos del DataFrame creado previamente en pandas, este ejemplo demostrará cómo visualizar los puntajes de varias personas mediante una gráfica de barras con Matplotlib. Esto te permitirá ver cómo combinar la manipulación de datos con pandas y la visualización de datos con Matplotlib de manera efectiva.
Gráfico de Barras:
# Crear una gráfica de barras para visualizar los puntajes
plt.figure(figsize=(8, 6))
plt.bar(df.index, df['Puntaje'], color= 'skyblue')
plt.xlabel('Personas')
plt.ylabel('Puntaje')
plt.title('Puntajes de las Personas')
plt.ylim(70, 100)
# Mostrar los valores de puntaje encima de cada barra
plt.show()
Al ejecutar el código en un entorno de desarrollo como Google Colab o Jupyter Notebook, obtendrás una gráfica de barras que muestra los puntajes de las personas en el DataFrame. Cada barra representa el puntaje de una persona, con los valores de puntaje mostrados encima de cada barra para facilitar la visualización de los datos.
La combinación de pandas y Matplotlib te permite realizar análisis de datos completos y visualizaciones efectivas en Python. Al integrar estas dos librerías en tus proyectos de análisis de datos, podrás manipular, transformar y visualizar datos de manera eficiente, lo que te permitirá obtener información valiosa y tomar decisiones informadas basadas en tus análisis.
Para profundizar en el uso de Matplotlib y adquirir habilidades avanzadas en la creación de gráficos y visualizaciones de datos, te recomendamos explorar la documentación oficial de Matplotlib y realizar ejercicios prácticos en un entorno de desarrollo como Google Colab o Jupyter Notebook. La práctica constante y la experimentación te ayudarán a dominar las capacidades de Matplotlib y a crear visualizaciones de datos impactantes para tus proyectos de análisis de datos.
Referencias
Bernard, J. (2016). Python Data Analysis with pandas. In: Python Recipes Handbook. Apress, Berkeley, CA. https://doi.org/10.1007/978-1-4842-0241-8_5
Hunter, J. D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3), 90–95. https://doi.org/10.1109/MCSE.2007.55
McKinney, W. (2010). Data Structures for Statistical Computing in Python. In S. van der Walt & J. Millman (Eds.), Proceedings of the 9th Python in Science Conference (pp. 56–61). https://doi.org/10.25080/Majora-92bf1922-00a
McKinney, W. (2022). Python for data analysis: Data wrangling with Pandas, NumPy, and IPython. O'Reilly Media, Inc. https://wesmckinney.com/book/
Nelli, F. (2018). Python data analytics with Pandas, NumPy, and Matplotlib.https://doi.org/10.1007/978-1-4842-3913-1
The pandas development team. (2020). pandas-dev/pandas: Pandas (Version latest) [Software]. Zenodo. https://doi.org/10.5281/zenodo.3509134